What are the Scaling Laws?
Large Language Models (LLMs) have revolutionized natural language processing in recent years, performing tasks such as summarization, translation, question answering and countless others...
A language model is characterized by about 4 main elements:
- The number of parameters , which represents the ability of the model to learn from the data. A model with more parameters has more flexibility to capture complex patterns in the data.
- The size of the training dataset , measured in number of tokens (a small piece of text, ranging from a few words to a single character).
- The compute budget used to train it (measured in FLOPs or floating point operations per second).
- The network architecture (we assume that all current powerful LLMs are based on the Transformer architecture).
It is now well known that increasing the number of parameters leads to better performance in a wide range of linguistic tasks. Some models like PaLM exceed 540 billion parameters.
The question is therefore: Given a fixed increase in the compute budget, in what proportion should we increase the number of parameters and the size of the training dataset to achieve the optimal loss ?
OpenAI Scaling Laws
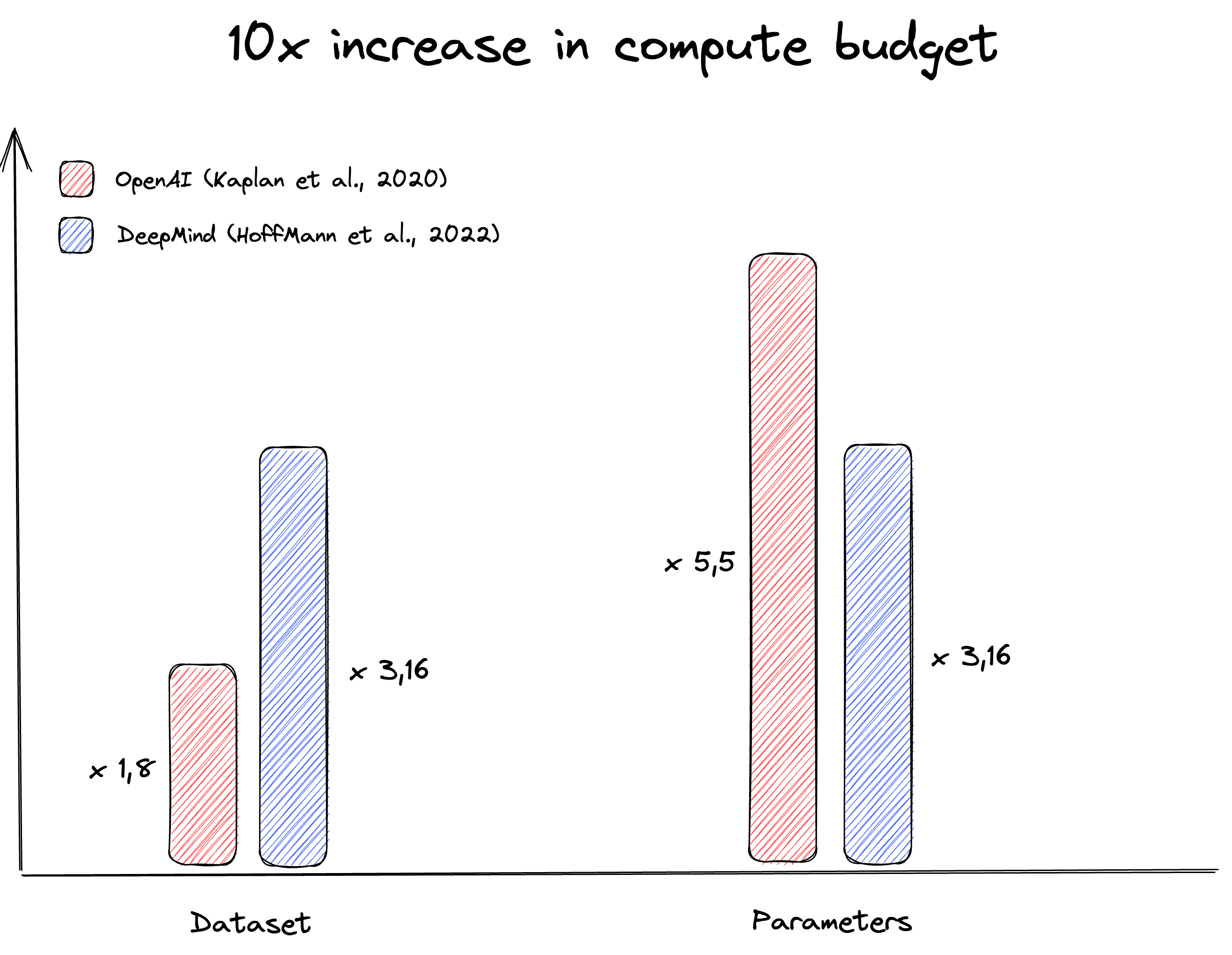
The trend to train increasingly larger models was motivated by a paper published by OpenAI in 2020 titled Scaling Laws for Neural Language Models.
This paper suggests that to train larger models, increasing the number of parameters is 3x more important than increasing the size of the training set.
Updated DeepMind Scaling Laws
However, another paper, published by DeepMind in 2022, shows empirically that increasing the size of the training data is just as important as increasing the number of parameters itself. They must be increased in equal proportions.
Moreover, training an optimal model requires about 20x more tokens than parameters.
Additionnally, recent research papers (InstructGPT, Chinchilla) has shown that an efficiently trained GPT model (with Reinforcement Learning from Human Feedback and lots of data) containing 1.3 billion parameters, equals in performance a GPT-3 model containing 175 billion parameters.
Thus, recent models that have not applied DeepMind's scaling laws are under-trained. See Gopher and PaLM below.
| Model | Parameters (in billions) | Tokens (in billions) | Loss (lower is better) |
|---|---|---|---|
| Gopher (DeepMind) | 280 | 300 | 1.993 |
| Chinchilla (DeepMind) | 70 | 1400 | 1.936 |
| PaLM (Google Brain) | 540 | 780 | 1.924 |
According to Approach 2 of the Chinchilla paper, Google would have had to train PaLM with about 14 trillion tokens to obtain the optimal loss¹ for a 540B parameters model.
How does increasing affect the model training?
Following the publication of OpenAI's Scaling Laws, AI research labs have tended to train models with a larger number of parameters, which has led to major advances in the field of training large neural networks (pipeline parallelism, tensor parallelism, ...).
However, the post-Chinchilla era poses major training challenges. More training data requires:
- More optimization steps (which cannot be easily parallelized)
- The increase of the batch size (which however degrades the performance of the model from a certain point)
The question is therefore: How to increase the data size while keeping a good training efficiency?
Right. Models are getting bigger and bigger, which has led to new challenges in how we train and process data. But what about their capabilities...
Emergent properties
By definition, emergence is when quantitative changes in a system result in qualitative changes in behavior. Emergent properties are not inherent to LLMs but appear in a wide range of other fields such as physics, biology, economics, ...
One ant alone is stupid, but if you put thousands of them together, they start to create ant hills, communication networks and thus behave like an intelligent community.
An amazing property of LLMs is the emergence of new capabilities as the size of the network increases. In other words, LLMs unpredictably learn to perform new tasks, without having been specifically trained to do so.

Pathways Language Model (PaLM): Scaling to 540 Billion Parameters for Breakthrough Performance
- Can we expect the solution of more complex problems to be accessible only at very large model scales?
- Would improvements in the learning algorithms allow for more efficient model training?
However,
- We do not know at what "scale" these emergent properties appear
- We lack knowledge about the ability of these models to deal with emergent properties
One problem persists: the amount of data available. Suppose we want to train a large model with 100 trillion parameters to study its emergent properties. According to the Chinchilla paper, this would mean training this model on a database of... 180 petabytes of text. We are simply running out of data since the entire Common Crawl dataset is "only" 12 petabytes at the time of writing...
Can we control LLMs?
LLMs can generate outputs that are untruthful, toxic, or reflect harmful sentiments.
Model alignment is a very important field of research today. An ideal model must have two essential qualities:
- Reliability, or being able to trust the answers produced by the model
- Controllability, or being able to control the model
Reinforcement learning from human feedback (RLHF) is often used as a way to make models safer, more helpful, and more aligned.
The Californian start-up Anthropic has discovered empirically that the capability for moral self-correction emerges at around 22B parameters. For more scientific details, the paper is here.
The models are getting bigger and bigger and some amazing properties are emerging from these LLMs at such scale. Is size the way to intelligence?
A silicon brain?
Questions remain about the similarity between the human brain and current LLMs. Here is a collection of 4 thoughts that came to mind or that I read about the similarities/differences between the brain and current neural networks.
A different optimization algorithm?
Many neuroscientists are convinced that the brain cannot implement backpropagation (the algorithm used to train neural networks), for the simple reason that the electrical signal produced by neurons propagates in only one direction.
Backpropagation requires a "forward" pass to compute the loss and a "backward" pass to modify the parameters.
The idea would be to create a "forward-forward" algorithm that approximates the correct properties of backpropagation, and that would relate to our biological model.
More neurons or more data?
In our brain, the number of neurons seems to play a very important role. It is the mutation of the ARHGAP11A gene 5 million years ago, which allowed a drastic increase in the number of neural stem cells in the neocortex (between 3 and 6 times more) and thus the development of new cognitive faculties such as reasoning or language.
Does the number of neurons play a more important role than data in a biological brain?
Artificial sleep
Sleep and its different phases (slow, deep, REM) plays a fundamental role in the functioning of any biological brain. However, the role that sleep plays on our intelligence is still to be discovered. Some hypotheses suggest a remodelling of the synapses leading to untimely tests of connections, to simulate problems and better anticipate them. No current artificial neural network offers a "sleep state" that would allow the knowledge acquired during training to be consolidated.
Could an "artificial" sleep promote the emergence of creativity in these deep neural networks?
Reasoning ability
To date, no neural network shows a capacity for reasoning and creativity worthy of an animal level.
Current LLMs are autoregressive models that predict the probability distribution of the next token given the set of previous tokens called context:

According to Ilya Sutskever, co-founder and Chief Scientist of OpenAI, these autoregressive models have the potential to achieve human-level intelligence, as the statistics, beyond the numbers, reveal an understanding of the underlying concepts.
Could finding a link between next word prediction accuracy and reasoning abilities be the way to bring the current autoregressive models to truly intelligent models?
References
- chinchilla's wild implications
- Emergent Abilities of Large Language Models
- Scaling Laws for Neural Language Models
- Training Compute-Optimal Large Language Models
- Interview with Ilya Sutskever
¹: According to the paper, the LM loss takes the following form:
with the number of parameters (in billions) and the number of tokens in the training dataset (in billions). The irreducible error captures the loss for an ideal generative process and corresponds to the entropy of natural language.